
No One Learns About Dat(a)ing By Reading Books About Dat(a)ing
Budget-Friendly Ways To Build AI #4

Know Your Data First
In this article, I’ll cover what is often referred to as Exploratory Data Analysis (EDA). What it really is just looking at data to understand what information it contains and how it contains that information. More specifically, EDA is about discovering how a dataset records different types of information, the range of values that each feature spans, their statistical distributions, relationships of each feature with one another and how and where various anomalies.
EDA is often done together by data engineers and data users because the 2 groups are the ones who really have to deal with the information part of the data. This is in comparison to people who handle how data flows through different channels, which is the job for ML engineers and infrastructure people. A simple analogy is that data engineers and data users are like people trying to make tap water safe to drink while ML engineers and infra people are like people who are working on figuring out how to get the water to places that need water regardless of whether it’s safe to drink.
EDA Doesn’t Cost Much But Not Taking it Seriously Will Cost You Later
Quick disclaimer, EDA doesn’t cost much to do, only needs to be done once per data set. What’s important is that if you don’t do EDA properly, it will multiply the amount of work that needs to be done by an unknown factor for people building AI models. And if you don’t do EDA at all, data users are going to be doing everything brute force. This is a cost suicide.

“Tell Me About Yourself, Miss/Mr. EDA”

Let’s skip the interview questions. We’re going straight to the deep stuff.
Catch Up On Technicals After This Article
There are some technical ways to go about this - various statistical distribution modeling techniques and statistical tests. There are also enough material on proper tooling - how to use packages like Pandas and NumPy. Readers who are not familiar with the technicals should read up on those after this article.
There’s Always More To Be Discovered In Your Data
Readers who are familiar should ask themselves what they are missing in their understanding. Be thorough. Good time to stop digging into your data is when you feel like there’s more to be discovered but you can’t find anything new after combing through it again a handful times.
Data-ing 101

This article is really meant to give readers a "view of the forest” rather than a “tree” when it comes to understanding your data. But some basics about how to understand your data well are necessary. So I will include some basics.
Red Flags In Your Data-ing Skills Create Resource Traps
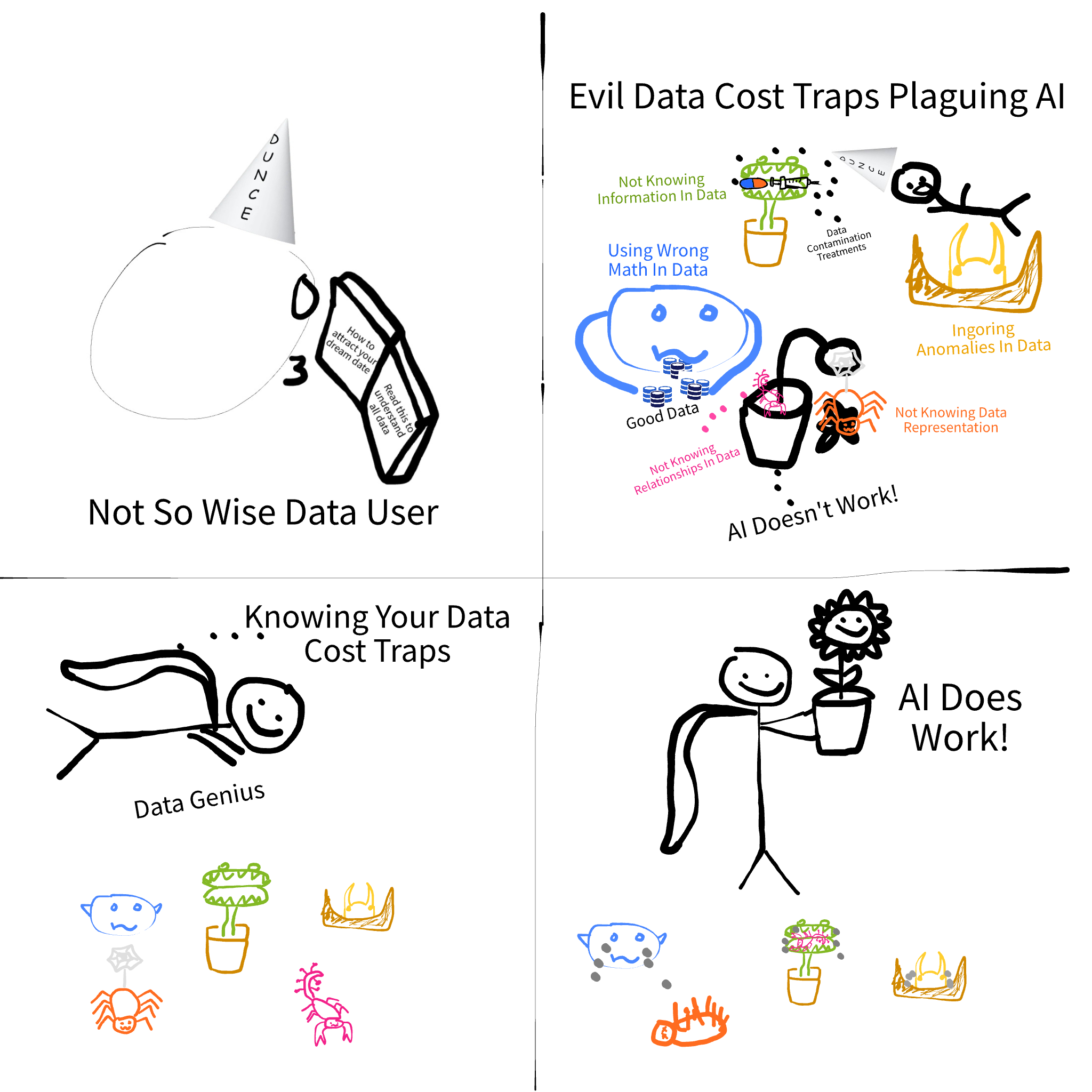
Being good at “data-ing” is simple. You have to be correct in your analysis and not skip any details. In practice, that means you have to be good at spotting the following red flags in your data-ing practice. I will order them in the order of biggest cost traps.
Incorrect analysis of mathematical nature of data
Incorrect analysis of information contained in data
Incorrect analysis of how the data is represented
Not knowing the source of anomalies
Incorrect analysis or forgetting to dig into relationship amongst features1
Beneath these red flags, are traps that will cost you. Readers may feel like it’s not a big deal or assume they can always come back and fix things but looking over the details do real damage. There’s no need to feel pain you don’t need to feel.

Danger of red flags is that the traps beneath will cost in all sorts of unpredictable ways. Fortunately, it’s possible to understand how each cost trap adds complexity. Remember, when you go on a journey of building AI, you’re in an open field. Anything that can kill you, will kill you if you’re not prepared.
Each of the red flag I mentioned have the following traps beneath:
AI models aren’t learning anything you want them to learn!
Fixing and testing AI models become useless.
Your AI model can become poisoned.
Your model won’t be able to handle edge cases and will surprise you when you least expect it.
Each number of relationship that exists that you forget about, less predictive power your model can have and harder to fix your model.
Caught In a Trap? Understand The Damages and Salvage What You Can
I am listing below how each cost trap adds resources and their complexities.
Incorrect Analysis of Mathematical Nature of Data Makes Models And Pipelines Useless: Adding Linear or Quadratic Costs With Respect to How Late Issues Are Discovered
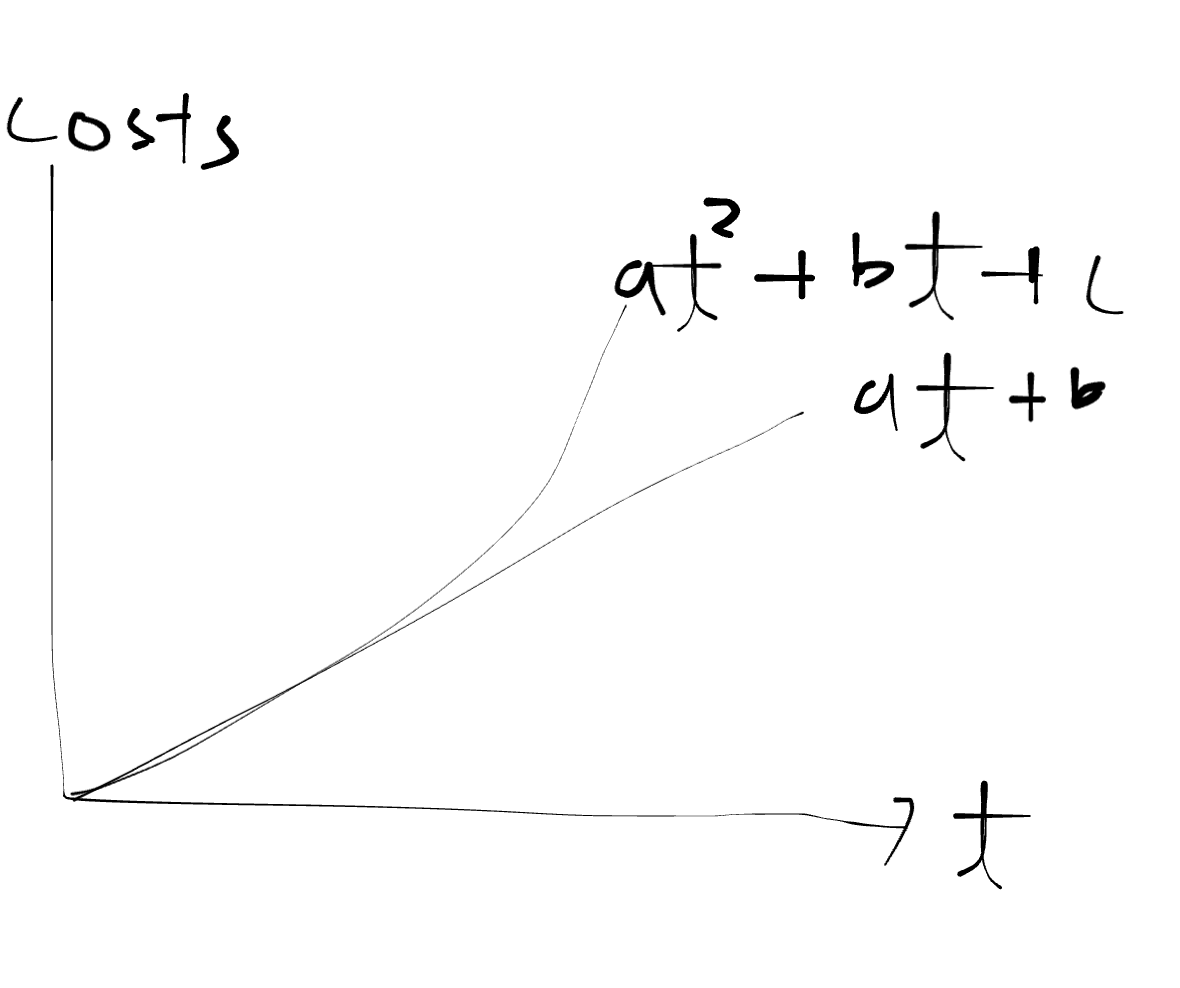
Again, the cost trap comes from the fact that AI models aren’t learning anything useful.
Real danger of this trap is that work done on both the data pipeline and modeling becomes completely useless. Only thing left to salvage is the team’s sanity.
If data pipelining and modeling are done in one team, what gets repeated is the same amount of work that needed to be done previously, which adds costs linearly.
If they are done by separate teams, then there’s a communication cost involved, which can start to add cost quadratically if not careful. For instance, if the modeling team discovered they’re caught in a trap, they must communicate this the pipeline team. What can happen is that while the pipeline team is working on finding a solution, the modeling team may go ahead and try to solve the problem on their own. They will be repeating many tasks that are going to be fruitless because the first thing that need to be done is re-doing the EDA and then fixing the data pipeline. If the data pipeline team comes up with a solution hastily, this process repeats. So for every iteration that a pipeline team goes through, the modeling team goes through multiple iterations.
Incorrect Analysis of Information Contained in Data Makes Model Test Results Undiagnosable: Adding Lump-Sum Costs per Architectural Milestone
You risk your AI model not being fixable as your test results cannot be diagnosed.
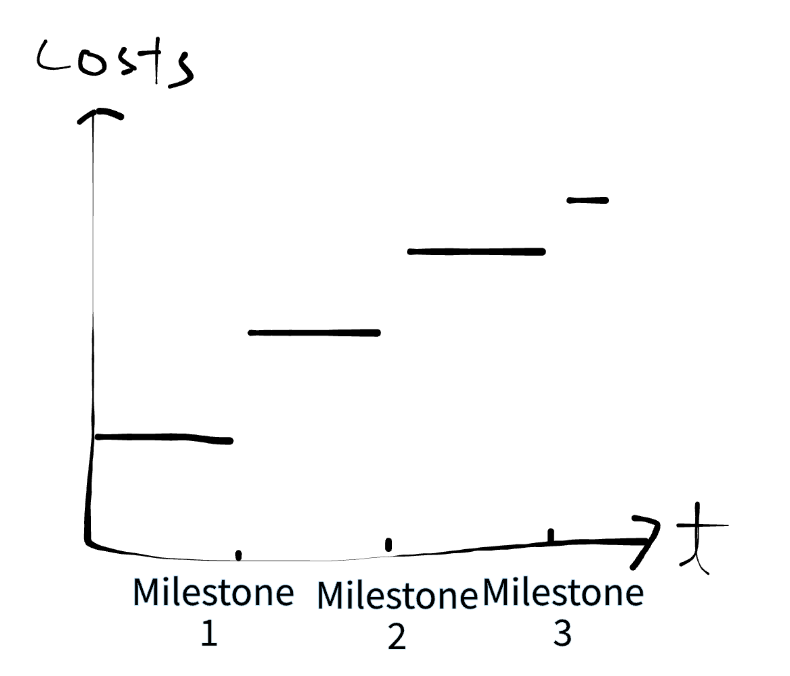
Danger of this trap is that you have to give up on the model architecture and re-do from scratch. This incurs both training and pure research costs, which is really personnel costs.
Every architectural milestone you hit on the modeling side, the amount of work that needs to be repeated increases as much as the work that needed to be done per milestone.
It’s a bit hard to predict whether what needs to be fixed is on the pipeline side or the model side as it depends on the exact nature of the data representation issue. This is left as a technical exercise and I recommend reading up on different types of data poisoning and what they look like in practice.
Incorrect Analysis of Data Representation Can Lead to Systemic Failures Or Allude to Security Risks
Data being represented in weird ways can poison your model - meaning your model thinks it’s doing one thing but it’s really doing other. This decreases the amount of trust that can be put into the model as it will behave strangely in some cases. If you don’t understand your data representation, any poisoning attempts won’t be caught.
Danger of this trap is that you have to create filters that get rid of poison in the data and train your model from scratch. Luckily your data pipeline and architectural framework should remain intact.
Cost addition in this case should be similar to above step function but without the need to re-do the architecture. It’s just compute costs from training the model.
Ignoring Anomalies or Failing to Understand Where They Come From Could Lead to Models Blowing Up In Production Because Edge Cases Won’t Be Handled
If your model doesn’t understand how to handle something it hasn’t seen before, it will not know how to handle it appropriately. There is no definitive way of prevent this but if there are known anomalies or if potential sources of anomalies are well understood, it’s much easier to handle edge cases where your model blows up.
Real danger is in the model blowing up part. Catching anomalies early makes a model healthy. There could be various operational costs involved especially if you take out some insurance on your model blowing up. But obviously, less anomalies you ar aware of, higher your premium is going to be.
Luckily, both the data pipeline and framework for model architecture should both be intact.
Incorrect Analysis Of Relationship Among Features Makes Models Less Powerful: Adding Costs Logarithmically Per Number of Relationships That Need To Be Discovered
There’s always a performance requirement to meet some standard of quality. And missing out on information in your data can be very damaging.

Don’t Read Between The Lines In Your Data Too Much
Avoiding traps is crucial but it’s also important not to overthink things. Do not make up conclusions about your data where there aren’t any. It’s best that your analysis is backed up by facts that come from people or entities who record the data.
Too Much To Read… There Will be Part 2 of This Article Next Week
I failed to keep this under 10 minutes again. Wait for Part 2 where I will cover how to really think about your data with examples.
Even with neural networks, which is meant to discover relationships among features automatically, this can be necessary especially when you need to make your model smaller.