
Iterate Quickly On Your AI Agents: Letting Intuition Guide You Vs. Only Trusting What You See
Budget-Friendly Ways To Build AI #6


This article describes mindsets that are critical to both AI engineers and AI scientists . I will cover what these mindsets are and how to view AI building as well as working with data through these mindsets.
Believers And Agnostics
Have you ever believed in something so much and it turned out to be true eventually? In statistics - which is the basis of modern AI1 - this is called being Bayesian2. Or maybe you are one of those people who only believe in what you see. We’d call you a Frequentist.
Neither is right or wrong. They are just 2 different ways to view the world of data and AI. And they are not always conflicting either. In fact, when you combine them, they can create immense synergy - letting you go from bootstrapping your AI to scaling it.
In this article, I will cover what the two mindsets are and when they should be adopted to effectively scale building AI systems. I will also cover what aspects of customer experiences can be enabled by adopting each mindset. I will also discuss what it means to adopt the 2 mindsets when dealing with data and building AI systems.
Bayesians Start With A Belief Then Update Their Beliefs With More Data
When Bayesians approach a problem, they form a “prior” first. A “prior” is just some specific version of your beliefs based on intuition that you can. “Prior” needs to be stated in clear logic and need to be updated as you collect more evidence.
Start With Intuition Then React Quickly To New Data
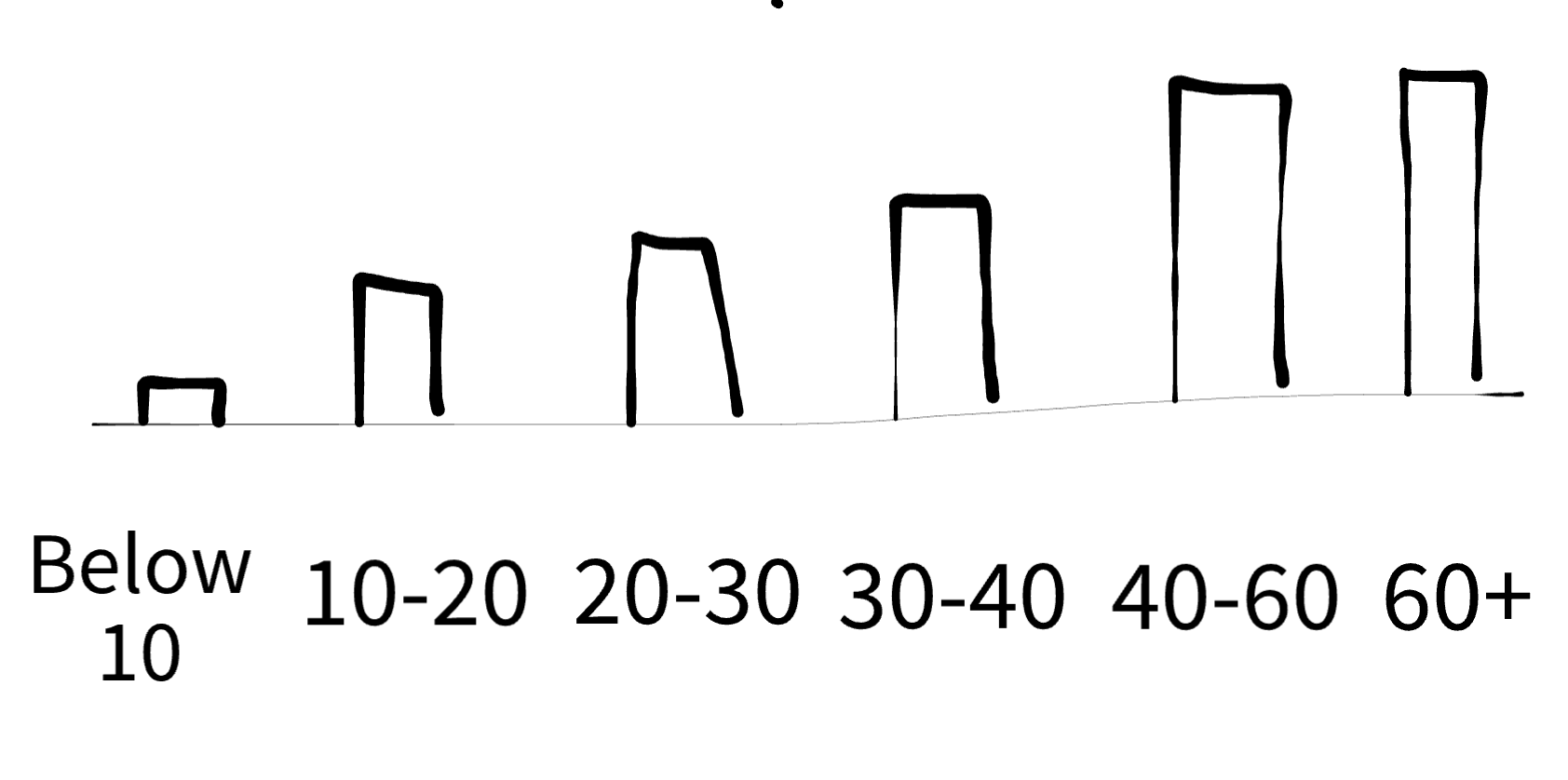
When working with data directly, this means turning an intuition about data into a specific statistical distribution. For example, let’s pretend I’m looking at data on sea mustard (aka wakame) consumption throughout different age groups in Korea3. Even before I look into the data, I already know that sea mustard is marketed as healthy food for longevity, so I might think that the consumption would be much higher for middle-aged and older people.
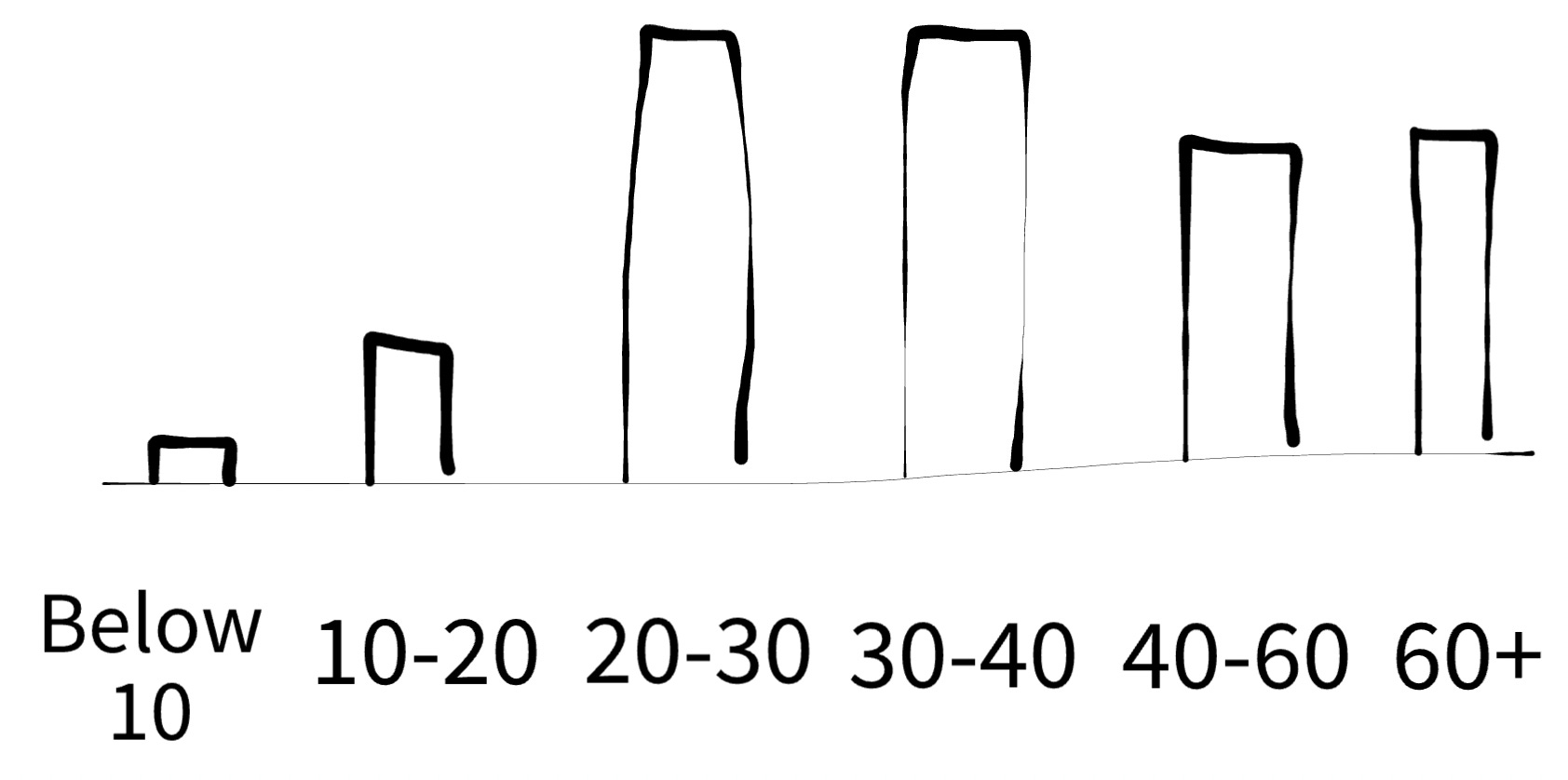
But all of a sudden, I come across new data points where sea mustard is being marketed to young people and career professionals who have to meet lot of clients as a hangover cure. Considering that I’m one of those young people, I might as well give it a try after my hangover. And then I start noticing that there are products out there that are grossing large revenues from younger people. Then I need to update my distribution of what ages groups consume more sea mustard.
Bayesians Figure Out a Plan To Make AI Systems Better Over Time
When building AI systems, forming a “prior” means documenting intuitions about the nature of the problem you want to solve and then coming up with candidates for how to build your solutions. It’s important to note here that the “prior” should contain a set of possible solutions and a good way to form this is to make sure you don’t have to overhaul anything within your set.
Let’s pretend that I’m trying to build an AI system that creates advertisements for sea mustard. If I start out thinking I can market to older people, I will start collecting prompts that are geared towards older people - bigger fonts, pictures that show the benefits of living longer like showing an old person with their kids and grandkids, etc…
But If I understand that things can change over time, I will have to be prepared for it. I’ll need to set up pipelines to collect information about kinds of contents that younger people like. As soon as my “distribution” of sea mustard consumption per age groups gets updated, I will need to activate those pipelines to make my AI system fit to changing consumption per age group.
Frequentists Wait Until They Have Enough Data And Only Trust Clear Evidence
Frequentists care about how frequently they see patterns, only if those patterns are verified. This mindset is much more suitable once you have enough information and therefor can start to scale things.
For instance, if I were to think like a frequentist, I would wait until I have enough data to form a distribution around how much each age group consumes sea mustard.
Build For Perfection Once Enough Data Is Collected And Verified
Going back to the sea mustard example, let’s assume that the Bayesian approach got us to a good start. I now have a working AI system that makes decent enough contents to promote sea mustard.
But I come across a handful number of new information - that in fact young people don’t eat sea mustard because they just think it’s a good hangover cure, but because they are very health conscious and tend to deep dive into nutritional contents and carefully plan their diet.
What I can do then is to figure out exactly how they research out nutritional contents and what types of goals they have for their health. I can send out a survey and collect this data. And then I can start analyzing specific patterns as to how and why people craft their own diets - some people might want to lose weight, gain muscular mass, or want to feel refreshed. And then I can start looking up how they like to consume, especially sea mustard. I could even start hosting tasting events.
Once I have enough information on how people research nutritional contents, how that related to their health goals, and ways they like to consume things then I can start building towards making my AI system much more targeted - making it really speak to young people.
Be Both Bayesian And Frequentist
Following our intuitions and beliefs on how something should be made is always a great start. But it needs to be substantiated by lot of good evidence eventually and data points that are collected need to be used in a way that is factual and impactful.
When you are starting to dig into your data set or building an AI system, start with an Bayesian approach. Have some intuition or set of beliefs that is supported by logic to start with. And then make sure to plan for uncertainty. Then once you have enough data points on how someone is using your AI and how else it might be improved on, take the frequentist approach.
Modern AI is mostly machine learning based, which is derived from statistics.
Coined after Thomas Bayes, a statistician and a Presbyterian minister.
Koreans do eat a lot of seaweed.